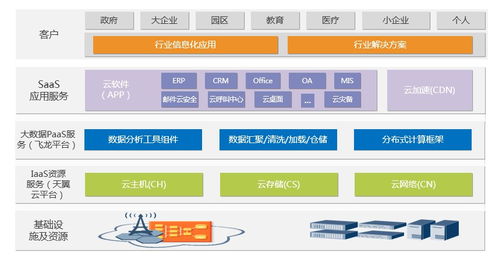
随着大规模语言模型(LLM)的蓬勃发展,训练千亿乃至万亿参数级别的模型已成为AI领域的前沿阵地。模型规模的指数级增长对底层的数据处理与存储支持服务提出了前所未有的挑战。优雅地训练大模型,不仅需要先进的算法与算力,更依赖于一套高效、可靠、可扩展的数据流水线与存储架构。本文将探讨如何构建这样一个支持体系,以应对LLM训练中的数据洪流。
一、 数据预处理:规模化与智能化的平衡
大模型训练始于海量、多模态、高质量的原始数据。优雅的数据处理首要在于预处理流程的工业级设计。
- 分布式数据摄取与清洗:利用如Apache Spark、Flink等分布式计算框架,构建可横向扩展的数据摄取管道,并行处理TB/PB级原始文本、代码、图像等多源数据。清洗过程需自动化识别并过滤低质量、重复、有害信息,同时结合小规模模型或规则引擎进行智能去重与内容安全过滤。
- 高效的Tokenizer与序列化:针对LLM,选择或训练合适的Tokenizer(如BPE、SentencePiece),并将其集成到高效的C++/Rust后端中,实现分布式分词与编码。将文本数据预处理为可直接用于训练的序列化格式(如TFRecord、HDF5、Arrow),并建立索引,以支持后续的快速随机访问。
- 版本化与可复现性:所有原始数据、清洗后的数据、分词词典及处理代码都应进行严格的版本控制(如DVC、Git LFS)。确保任何一次训练任务的数据 lineage 清晰可溯,这是科学实验与工程可复现性的基石。
二、 存储架构:性能、成本与可靠性的三重奏
训练过程中,数据需要被高速、反复读取。存储系统的设计直接决定了训练效率的上限。
- 分层存储策略:
- 热存储(高性能):使用全闪存阵列或高性能分布式文件系统(如Lustre、GPFS、WekaFS)存放当前训练周期正在频繁访问的预处理后数据集。其超低延迟和高IOPS是保证GPU算力不被闲置的关键。
- 温存储(高吞吐):采用基于对象的存储(如AWS S3、Google Cloud Storage、MinIO)或HDFS,作为中心化的数据湖,存放所有版本的处理后数据集、检查点、日志等。它提供高吞吐的顺序读写能力,适合数据加载和模型保存。
- 冷存储(低成本):将不常访问的原始数据、历史检查点归档至磁带库或冰川类存储服务,以极低成本满足长期保存需求。
- 缓存与数据局部性优化:在计算节点(GPU服务器)本地NVMe SSD上设置智能缓存层。训练开始前,将当前任务所需的数据块预加载至本地缓存;训练过程中,采用优化的数据加载器(如PyTorch的DataLoader,结合WebDataset格式)实现流水线化,使数据准备与GPU计算完全重叠,消除I/O瓶颈。
- 持久化与容错:所有关键数据(原始数据、中间数据、模型检查点)必须在分布式存储中拥有多副本或纠删码保护。定期将训练检查点同步至对象存储,确保在发生硬件故障时能快速从最近状态恢复,避免数日计算成果毁于一旦。
三、 服务化与协同:提升研发效率
优雅的体系最终要服务于研发团队,降低其数据管理负担。
- 数据服务化:构建内部的数据平台或服务,提供统一的目录查询、数据预览、样本检索、质量报告和自助式数据订阅功能。研究人员可以通过API或界面轻松获取所需版本的数据集,而无需关心底层存储位置与格式。
- 与训练框架深度集成:数据处理管道应与PyTorch、TensorFlow、JAX等训练框架无缝对接。例如,利用NVIDIA的DALI库进行GPU加速的数据预处理,或使用Ray Data、TensorFlow tf.data API构建端到端的分布式数据流水线,让数据像水流一样自然流入模型。
- 监控与洞察:建立全面的监控系统,跟踪数据流水线各阶段的吞吐量、延迟、错误率以及存储系统的容量、IO性能。利用这些指标持续优化数据流水线,并快速定位瓶颈。
四、 面向未来的考量
- 持续学习与数据迭代:LLM需要持续进化。数据处理体系应支持增量数据的无缝接入、与已有数据的融合去重,以及面向新任务的动态数据采样与混合策略。
- 合规与隐私:在处理海量公开数据时,必须内置数据版权过滤、个人信息脱敏机制,并建立数据使用审计跟踪,以满足日益严格的法规要求。
- 成本优化:通过数据压缩(如Zstandard)、智能生命周期管理(自动将冷数据迁移至廉价存储)、按需供给等策略,在保证性能的控制庞大数据工程的总拥有成本。
在LLM盛行的今天,“优雅地训练大模型”是一场系统工程的艺术。其核心在于认识到数据是模型的“第一性原理”,并围绕这一原理,构建一个兼具自动化处理能力、高性能存储访问、强韧服务化支持的数据基础设施。唯有如此,才能让宝贵的算力资源完全聚焦于模型本身的创新与突破,从而在AI竞赛中赢得先机。