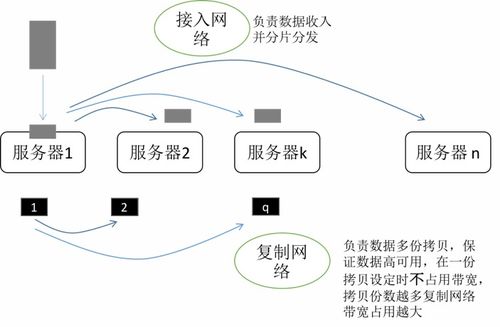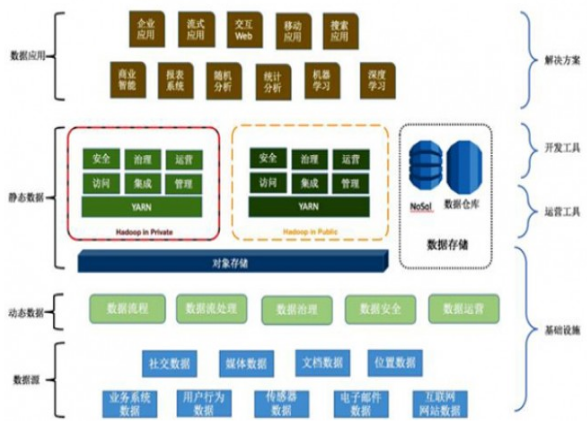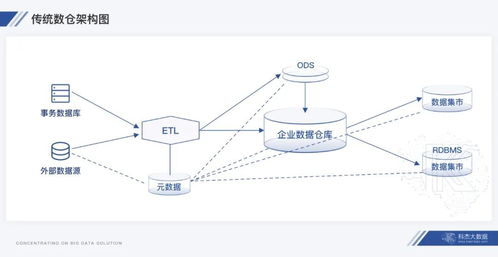
在数据驱动的时代,数据处理与存储架构的演进从未停歇。过去,企业常在数据仓库(Data Warehouse)与数据湖(Data Lake)之间艰难抉择:数仓强于结构化数据的高性能分析,但扩展性、成本及半/非结构化数据处理能力有限;数据湖能以低成本存储海量原始数据,格式灵活,但易沦为“数据沼泽”,缺乏可靠的数据治理与高效的查询性能。如今,一种融合二者优势的新范式——湖仓一体(Lakehouse)正冉冉升起,它并非让数仓或数据湖“退出群聊”,而是引领它们走向更高阶的融合与统一,成为企业数据架构进化的下一站“灯塔”。
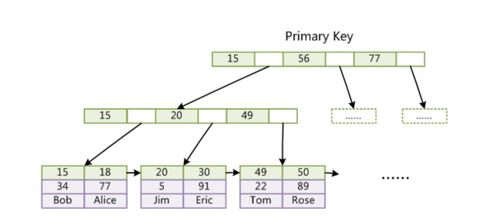
湖仓一体架构的核心在于,在低成本、可扩展的数据湖存储层之上,构建了类似数据仓库的数据管理与事务处理能力。它通过开放式格式(如Apache Parquet、Delta Lake、Iceberg等)存储数据,并支持ACID事务、数据版本管理、完善的元数据层以及统一的访问接口。这意味着,企业可以在同一个平台上,同时完成数据工程、数据科学、机器学习与商业智能分析,无需在数仓与数据湖之间进行繁琐、易错的数据迁移与复制。
这一架构为数据处理和存储支持服务带来了根本性变革:
- 统一性与简化治理:湖仓一体打破了“湖”与“仓”之间的壁垒,提供了一个单一的数据源头。数据一旦入湖,即可被各类分析与机器学习工具直接消费,极大简化了数据管道,减少了数据冗余。统一的安全、治理与元数据管理策略贯穿始终,有效提升了数据质量、一致性与合规性。
- 性能与成本的最优解:它继承了数据湖使用低成本对象存储(如云上S3、ADLS)的优势,同时通过智能缓存、索引优化、数据布局优化(如Z-Ordering)及向量化查询引擎等技术,实现了接近甚至超越传统数仓的交互式查询性能。企业不再需要为性能和成本做痛苦权衡。
- 支持多样化的数据与工作负载:无论是结构化的交易数据,还是半结构化的日志、JSON,乃至非结构化的图像、文本,湖仓一体都能原生支持。它无缝衔接了从ETL/ELT批处理、实时流处理到高级分析与AI模型训练的全场景工作负载,赋能更广泛的数据驱动创新。
- 开放的生态系统:基于开放格式和标准(如Apache Spark、Presto/Trino),湖仓一体避免了厂商锁定。用户可以选择最适合的工具链,从计算引擎到BI工具,构建灵活、可互操作的数据栈。
湖仓一体并非终点,而是数据架构持续演进的关键里程碑。它标志着数据处理范式从“分离与复制”走向“统一与融合”。对于寻求数字化转型的企业而言,拥抱湖仓一体意味着构建一个既能应对当前海量、多态数据挑战,又能灵活适应未来AI/ML爆发式增长需求的现代化数据基座。数仓与数据湖的精华在此汇聚,共同照亮数据价值深度挖掘与业务敏捷创新的前行之路。