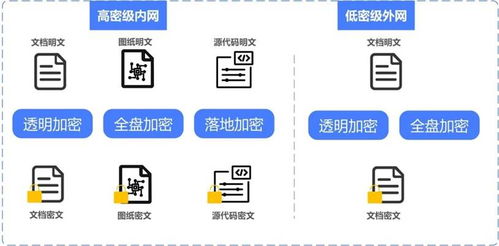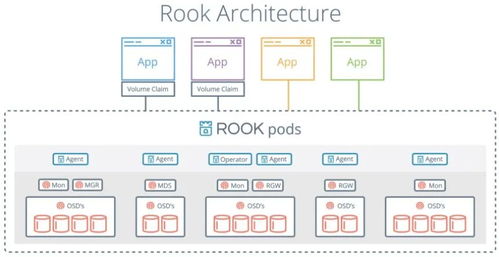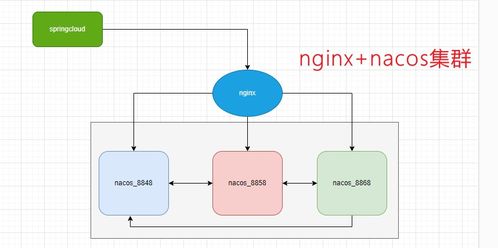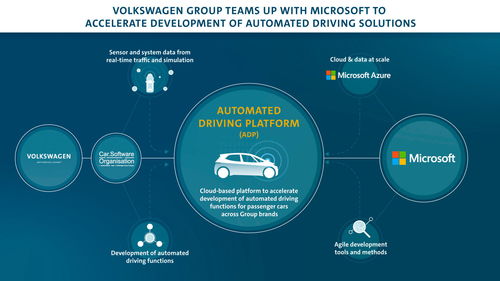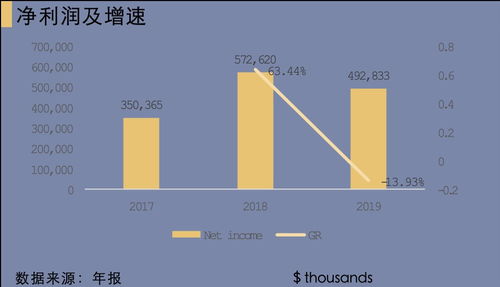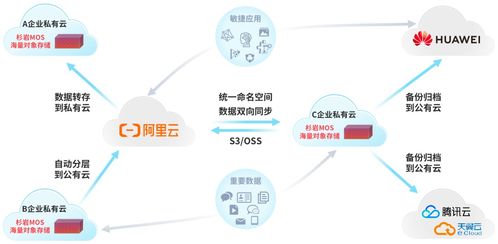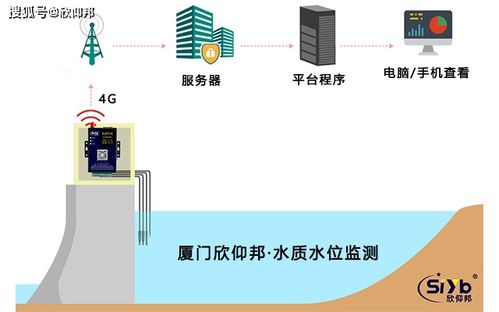
随着互联网的快速发展,海量数据已成为各行各业的重要资源,简单爬虫架构作为数据采集的主要手段之一,在数据处理和存储支持服务方面发挥着关键作用。本文将从核心技术、实现流程和优化策略等角度系统分析简单爬虫架构中数据处理与存储支持服务的构建。
一、爬虫架构与数据处理概述
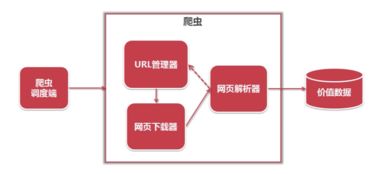
简单爬虫架构通常包含调度器、下载器、解析器、数据处理模块和存储模块五个核心组件。其中,数据处理和存储支持服务直接决定了爬虫系统的可用性和扩展性。数据处理指对抓取的网页进行清洗、去重、格式化和结构化处理的过程,而存储支持服务则需保证数据的高效写入、查询和管理。
二、数据处理的关键技术
- 数据清洗:去除网页中的无关信息,如广告、版权声明和HTML标签。借助正则表达式或BeautifulSoup等工具实现。
- 数据去重:通过布隆过滤器或哈希算法避免重复采集,有效节省存储资源。
- 结构化转换:将非结构化的网页内容转化为结构化的JSON、CSV或数据库记录,便于后续分析使用。
三、存储支持服务的实现方式
- 文件存储:适用于小规模数据,将处理后的数据保存为本地文件,如CSV、JSON或TXT格式。
- 数据库存储:关系型数据库(如MySQL)适用于结构化数据的快速查询,非关系型数据库(如MongoDB)则更擅长存储半结构化的网页内容。
- 分布式存储:当数据量较大时,采用HDFS或云存储(如AWS S3)提供高可用性和可扩展性。
四、优化策略与实践建议
- 异步处理:采用异步I/O和消息队列(如RabbitMQ)提高数据处理效率。
- 缓存机制:将频繁访问的数据存入Redis等缓存系统,减轻数据库压力。
- 容错设计:通过断点续传和数据备份机制确保系统在异常情况下的稳定性。
五、总结
简单爬虫架构中的数据处理和存储支持服务是保障数据质量和系统性能的核心环节。合理选择技术方案,结合异步处理和分布式存储,能够显著提升爬虫系统的整体效率与可靠性。随着人工智能和大数据技术的发展,智能化的数据处理与存储服务将成为爬虫架构演进的重要方向。