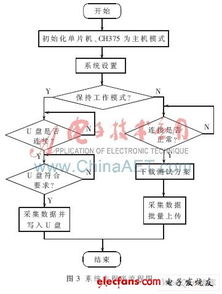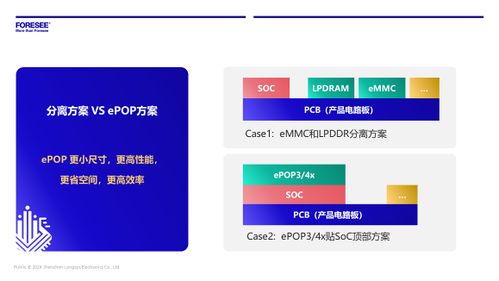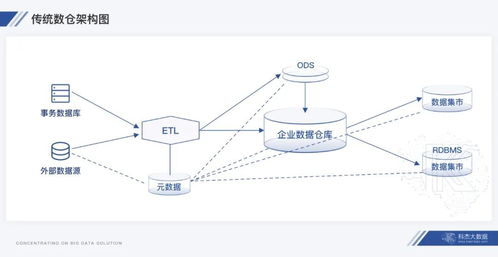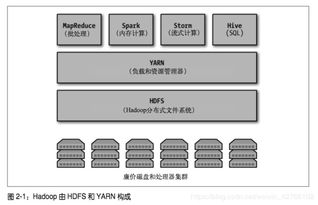
在《Hadoop数据分析》的第二章中,作者深入探讨了作为大数据核心基础设施的“大数据操作系统”概念,并着重分析了其数据处理和存储支持服务。本章内容揭示了Hadoop生态系统如何扮演类似传统操作系统的角色,为上层应用提供基础资源管理和服务支撑,而数据处理与存储正是其两大基石。
一、 数据处理支持服务:批处理与交互式查询的引擎
数据处理是大数据价值实现的关键环节。Hadoop生态系统提供了多样化的处理框架以满足不同场景的需求:
- 批处理引擎(MapReduce):作为Hadoop最初的编程模型,MapReduce通过“分而治之”的思想,将大规模数据集的处理任务分解为Map(映射)和Reduce(归约)两个阶段。它擅长处理海量历史数据的离线分析,其高容错性和可扩展性是其核心优势。其多阶段磁盘I/O的特性也导致了较高的延迟。
- 交互式查询引擎(Hive, Impala):为了满足更快的即席查询需求,以Hive(基于MapReduce或Tez/Spark)和Impala(MPP架构)为代表的SQL-on-Hadoop工具应运而生。它们允许用户使用熟悉的SQL语言对存储在HDFS或HBase中的数据进行查询和分析,极大地降低了大数据分析的技术门槛,提高了开发效率。
- 流处理引擎(Spark Streaming, Flink, Storm):对于需要实时或近实时处理无界数据流的场景(如日志监控、实时推荐),Spark的微批处理、Flink的纯流处理以及Storm等框架提供了强大的支持,实现了从“存储后分析”到“运动中分析”的范式转变。
二、 存储支持服务:分层化与多元化的数据湖仓
可靠、可扩展且经济的存储是数据处理的前提。Hadoop的存储体系已从单一的HDFS演变为一个层次分明、功能互补的生态系统:
- 分布式文件系统(HDFS):作为基石,HDFS以“一次写入、多次读取”的模式,将超大文件分块存储在廉价的商用服务器集群上,提供了极高的吞吐量和容错能力。它是原始数据、清洗后数据以及需要批量处理数据的主要归宿。
- NoSQL数据库(HBase):建立在HDFS之上的HBase是一个分布式、列式存储的NoSQL数据库。它支持海量数据的随机、实时读写访问,非常适合作为需要低延迟查询的在线应用(如用户画像查询、消息历史记录)的存储后端,弥补了HDFS在随机访问能力上的不足。
- 数据仓库与数据湖(Hive, Kudu):Hive的表结构(Metadata)管理能力,使其在HDFS之上构建了一个逻辑数据仓库。而像Kudu这样的存储引擎,则试图融合HDFS的吞吐量和HBase的随机访问性能,为需要同时支持快速分析查询和实时更新的场景提供了新的选择。
三、 协同工作与核心思想
数据处理与存储服务并非孤立运行。一个典型的数据管道可能是:原始日志实时摄入Kafka,由Spark Streaming进行初步处理和清洗后,将结果写入HDFS作为长期归档,同时将聚合后的关键指标写入HBase供仪表盘实时展示;而周期性的深度分析任务则由Hive或Spark SQL在HDFS的数据上运行。
本章的核心思想在于阐明,一个成熟的大数据操作系统(以Hadoop生态为代表)通过提供多元化的处理范式和分层化的存储方案,使企业能够根据数据的特性(体量、速度、多样性)和价值密度,灵活地选择性价比最优的技术组合,从而构建起一个统一、弹性、高效的数据平台。这为实现从数据到洞察、再到决策的完整价值链奠定了坚实的技术基础。
思考与启示:随着云原生和存算分离架构的兴起,大数据操作系统的内涵正在不断扩展。但无论如何演变,其对数据处理与存储基础服务的抽象、管理与优化,始终是支撑一切上层智能应用的根本。